Introduction
The CloudFiles: Process Document Using AI flow action is a foundational step for working with documents in CloudFiles Document AI. Before you can query a document, it must be processed first. In other words, just as you would upload a file to an AI system to later ask questions about it, CloudFiles requires this initial processing to make the document accessible for querying. The Process Document Using AI action handles this, preparing the document for subsequent queries.
This processing is an essential prerequisite for any workflow that involves further CloudFiles Document AI actions (For example, Query Document/Dataset) analyzing document content or extracting specific details, such as identifying document type or pulling specific values for other fields.
What this action does
This action runs asynchronously, meaning it does not provide immediate output. The Process Document Using AI action converts documents, such as images or PDFs, into a digitized, queryable format that CloudFiles can interpret. Instead of returning output directly, it publishes a Document Processed event once the processing is complete. This event details include ProcessedDocumentId (a unique CloudFiles identifier), which is essential for further CloudFiles Document AI actions, enabling you to query and interact with the document’s contents in subsequent flows.
Consider a scenario where you need to process KYC documents attached to Contact records in Salesforce, such as passports or national identity certificates. You may want to automatically identify the document type (e.g., “Is this document a passport?”) and, if it is, query additional information such as the address or nationality to populate fields on the Contact record.
To enable this process, you would:
Create a flow that triggers each time a document is attached to a Contact record and uses the Process Document Using AI action to make the document ready for querying.
Set up another flow triggered by the Document-Processed event, which references ProcessedDocumentId (a unique CloudFiles identifier) and information to identify its origin (such as the specific Contact record and processed file details) and use other CloudFiles Document AI actions to query and gather further information from the file.
This setup allows you to automate document classification and content extraction workflows effectively.
Input Parameters
In your Flow Builder, search for the element named "CloudFiles: Process Document using AI". You can find this action in the CloudFiles category when you click on the "Action" element in the "Add Element" box. Select the action to insert it into the flow, and then configure the input parameters.
To process a Salesforce file
In order to specify a Salesforce file to be processed, Input paramters as:
Library - salesforce(please note the parameters are case sensitive)
FileID - The ContentDocumentID of the Salesforce File to be processed.
You can get the ContentDocumentID of the Salesforce File from other standard salesforce elements like "Get Records" or standard Screen Flow "Upload Files" component or from details of CloudFiles Events like Salesforce File Attached.
- You can only process a Salesforce File in ContentDocument format.
- You cannot process an Attachment i.e. Classic Salesforce File format.
- It is mandatory to input both Library and FileID to specify a Salesforce File.
To process an external storage file
If you are using CloudFiles: Document Management package as well, then you can Process a file in connected external storage as well.
In order to specify an External Storage File to be processed, Input parameters as:
Library - The Library parameter is the external storage type you are using. Possible values are sharepoint, google (for Google Drive), onedrive, dropbox, box, azure, cloudfiles (for AWS S3). Please note the parameters are case sensitive.
Drive ID - The Id of the drive where the document resides. This is important for Google Drive & Sharepoint libraries only. The Drive Id is a unique identifier for a storage location in both SharePoint and Google Drive. In SharePoint, it represents a document library within a site, while in Google Drive, it identifies a user's drive or shared drive.
FileID - The unique identifier (Resource Id) of the file that is to be processed.
Based on the use case, you can get these parameters from details of other CloudFiles Events like File Uploaded or File Received etc.
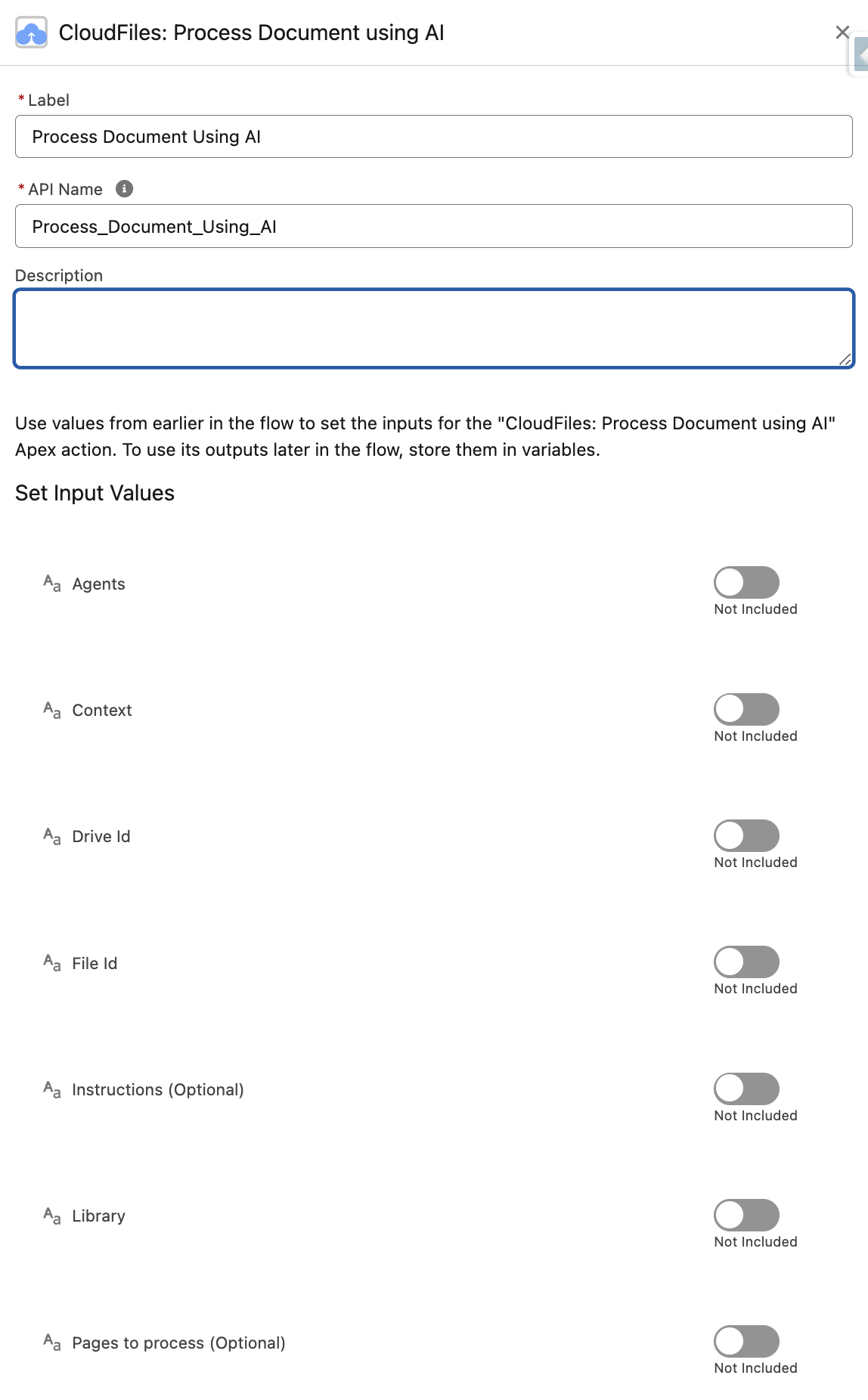
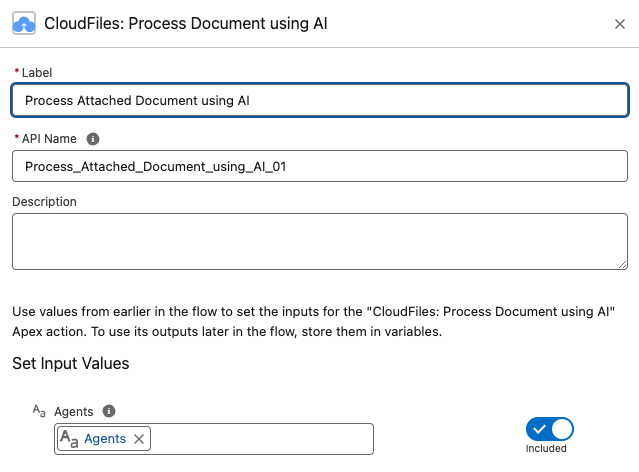
Agents (Optional)
CloudFiles Document AI uses different types of agents (or AI models) to process and query documents. Agents define how documents are interpreted and how queries are executed.
There are 3 possible types of agents that the Process Document action can accept as inputs - cloudfiles-searis-v1, cloudfiles-searis-v2, and cloudfiles-searis-aux-v1. The list of agents must be passed in a collection variable using the Assignment operation in flow.
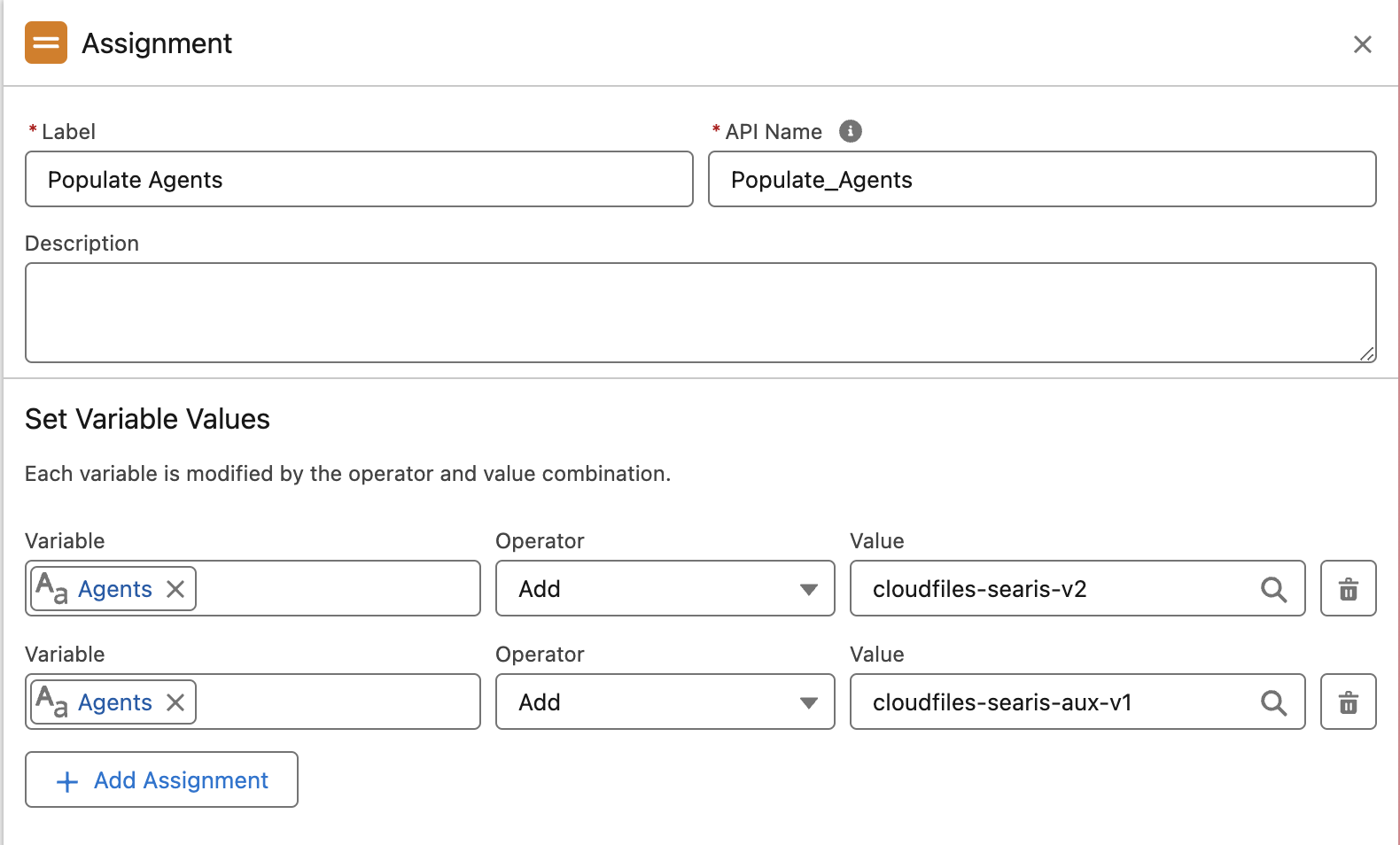
This collection variable can then be directly passed to the CloudFiles Process Document using AI flow action.
To know more about these agents, their capabilities, and when to use which agent, please refer to the About the Agents article.
Context
An optional identifier to track the source of the event or any other intended/necessary details. This shall be available in corresponding output i.e. in the corresponding Document Processed event details.
The Context parameter is particularly helpful if this action is used in multiple flows. For example, if you’re processing documents attached to Contact records, you can set the Contact’s Record Id as the Context. When events are published, this Context value will help you track the origin of each event by showing the associated Contact record.
Instructions (Optional)
The Instructions input parameter allows you to guide CloudFiles Document AI with specific context or expectations when processing a file. Providing clear, relevant instructions can significantly improve processing speed, classification accuracy, and downstream data extraction.
This is especially useful when dealing with complex, merged, or multi-section documents where a general understanding may not be enough for precise parsing.
- Improves AI interpretation by narrowing the context.
- Helps AI focus on document structure or content types.
- Reduces ambiguity in document classification or segmentation.
- Optimizes performance by pre-defining what the AI should look for.
You are provided with a Purchase Order document that includes summary information and detailed line items. Your task is to accurately extract structured data from the document. The common components you should recognize and extract include: PO Number – A unique identifier for the purchase order, often found at the top or in a header section. PO Date – The date the order was created or issued. Vendor Information – The name, address, and contact details of the supplier/vendor. Buyer Information – The name, address, and contact details of the purchasing organization or department. Shipping/Billing Address – The address where the goods should be delivered or address used for invoice and payment processing. Currency – The currency in which the order is being placed (e.g., USD, EUR). Order Line Items – For each line item, extract the following: Item Description, Item Code / SKU, Quantity, Unit Price, Total Line Amount (Quantity × Unit Price), UOM (Unit of Measure),Grand Total – The final total payable amount. Payment Terms – Specified terms for invoice payment (e.g., Net 30, advance payment). Delivery Terms / Incoterms – If provided, terms related to delivery responsibility. PO Notes / Special Instructions – Any additional notes, disclaimers, or delivery instructions included in the document. Ensure accurate mapping of each order line item as a separate object if needed for downstream automation (e.g., creating Order Line Items in Salesforce). Handle tables and lists carefully, preserving row integrity.
Pages to Process (Optional)
The Pages to Process parameter allows you to control which parts of a document are processed, instead of always running Document AI on the entire file. By default, CloudFiles processes all pages in the document. If you only need specific sections, you can provide the page numbers or ranges in a comma-separated format. For example:
1-3,5,7 will process pages 1 through 3, page 5, and page 7.
1,10,12 will process only pages 1, 10, and 12.
This parameter is especially useful when working with large multi-page files where only certain sections are relevant, helping to speed up processing and reduce unnecessary extraction.
Output Parameters
The apex action does not return anything as an output in the flow it is used but for every file processed a Document Processed event is published. This event signals the completion of file processing and can be used to trigger platform event flows to perform post-processing actions such as Query Document/Dataset or Query Document/Dataset (Batch).
If the action fails due to some reason, an error-event event will be triggered and this event can be used in a decision element to diagnose and handle the error.